Dr Aruna Dayanatha PhD
Move fast and break things? In the era of AI-assisted development, “vibe coding” – rapidly building software by prompting AI coding assistants – is both celebrated and maligned. Yes, it can take you from idea to prototype in record time. But critics highlight how this fast-and-loose approach often leaves a trail of bugs, security gaps, and spaghetti code in its wake. Is the speed and vibe of AI-driven coding really to blame for buggy software? Or is something deeper missing? This article makes the case that the core problem isn’t moving fast – it’s the lack of structure and memory in how we wield these AI tools. By shifting from ad-hoc prompting to an AI-augmented software development lifecycle (SDLC) grounded in persistent knowledge and orchestration, we can harness the creative “vibe” without the chaos.
Read on to discover how Problem-Approach Engineering, Notion-driven memory, and structured prompt libraries can transform vibe coding from a fragile stunt into a reliable, scalable practice. We’ll compare the unstructured vibe coding free-for-all with a more orchestrated approach – and show how Notion + LLM + Agile can function as a new “cognitive operating system” for building software. If you’re a CTO, developer, or tech leader wondering how to tame AI coding for the enterprise, this is your roadmap.
The Vibe Coding Backlash: Speed Without Discipline
Vibe coding captures the exhilaration of rapid, AI-assisted development – but without discipline, its “move fast” energy can lead to broken code and burnt fingers.
For the uninitiated, vibe coding refers to an AI-driven development approach where you use AI tools (like LLM-based pair programmers) and natural language prompts to rapidly generate and refine code, prioritizing speed and iterative feedback. In practice, it feels like coding by conversation – you describe what you want, the AI writes code, you tweak and repeat. It’s creative, fast-paced, and, well, vibey. Teams have reported development cycles up to 40% faster using this method, and non-developers can even join the party by describing features in plain English. It’s a paradigm shift in how we translate ideas into software.
However, 2025’s headlines have also been splashed with vibe coding fails. Think AI scripts gone rogue and deleting production databases, or rushed AI-generated apps riddled with security holes. A Tea App built via vibe coding infamously leaked user data on launch day because the team skipped security checks in favor of raw velocity. Consultants recount encountering “over-engineered, unmaintainable code” – overly complex systems filled with bugs and technical debt – churned out by overzealous AI assistance. And developers themselves admit their programming fundamentals start slipping after leaning on AI for everything.
The knee-jerk reaction might be: “Slow down! This vibe coding stuff is too reckless.” Indeed, the incidents have underscored the need for more discipline and oversight when integrating powerful AI into dev workflows. But does that mean the speed and AI-driven vibe are inherently bad? Not necessarily. As one observer noted, these fiascos don’t invalidate the methodology – they just highlight that rapid iteration requires equally rapid responsibility. In other words, vibe coding needs a guidance system and safety rails. The real issue is not that developers are coding too fast or “feeling the vibe” too much – it’s that the process often lacks memory and orchestration. Let’s unpack that.
The Real Culprit: No Memory, No Orchestration
What often causes vibe-coded projects to go off the rails isn’t the velocity; it’s the ephemeral, fragmented way they’re executed. Traditional software engineering has decades of practices for managing complexity – design docs, version control, issue trackers, code reviews, test suites, architectural patterns, you name it. Vibe coding in its naïve form tends to throw a lot of that out the window. Developers jump from one AI prompt to the next, generating chunks of code on the fly, often without a persistent plan or shared memory of decisions made along the way. It’s like collaborating with an extremely productive yet amnesiac partner – one who pumps out code in real-time but forgets what it did an hour ago.
Why is this a problem? Because building software is a cumulative process. Without long-term memory or structured coordination, the AI may literally rewrite history or repeat mistakes. AI coding assistants (especially LLM-based agents) have limited context windows – they can’t remember everything from earlier prompts unless you explicitly feed it back to them. As AI expert Steve Yegge wryly noted after a year of daily vibe coding, large language models will notice bugs “but fail to act on them in any way” if those issues aren’t immediately addressed, simply because they run out of context and forget. Critical problems end up lost or repeatedly rediscovered because they were never recorded persistently. In an unstructured vibe coding session, the AI might fix one bug, introduce another, then later re-introduce the first bug because it forgot the fix. It’s groundhog day in code.
Lack of orchestration is the other side of this coin. Orchestration means having a clear process or framework that the AI and human are following – akin to an agile sprint plan or a project roadmap. In free-form vibe coding, there’s often no single source of truth for what the system should do or what tasks remain. The AI may generate a high-level plan in one prompt, but after a few rounds of code and fixes, that plan is outdated or ignored. Yegge describes how an ambitious AI agent will start with a plan of six phases, work through a couple, then forget and start a new plan within the plan, eventually drowning in a dozen abandoned TODO lists. This “descent into madness” happens because there’s no anchored, persistent plan that the agent adheres to. Every time it loses the thread, it starts improvising again from scratch – a recipe for inconsistency.
In short, the chaos associated with vibe coding stems from memory loss and lack of coordination more than the concept of rapid AI assistance itself. What’s needed is not to jettison the vibe, but to ground it. Imagine if your AI pair-programmer had an external brain – a knowledge base of the project’s requirements, a log of all known issues, a history of design decisions – and a steady process to follow. That is where the solution lies.
AI-Augmented SDLC: From Ad-Hoc Prompts to Engineered Process
It’s time to evolve vibe coding into a more sustainable form: an AI-augmented Software Development Life Cycle. This means applying the same rigor we use in traditional development, but in a way that’s compatible with AI agents in the loop. Think of it as moving from freestyle jazz to a well-conducted symphony – you still get improvisation and speed, but within a structure that ensures harmony.
Problem-Approach Engineering. A key part of this shift is what some have dubbed “Problem-Approach Engineering.” Instead of treating each prompt as a one-off trick to get a code snippet, developers act more like AI project managers, defining the problem and approach in a structured way for the AI to execute. In other words, emphasis moves from clever prompt wording to higher-level planning and orchestration of prompts. As one report put it: *“Prompt engineering is valuable… but it’s the approach engineering – the structured way a user frames and navigates a problem – that defines success.”*. The approach (your game plan) sets the framework, and prompt engineering then executes specific steps within that framework.
Practically, this means you start by breaking the problem into sub-problems, just like a good software design. You might use AI to generate an architecture proposal or to outline components needed. But you capture that outline in a durable form (say, a design doc or an issue tracker) that persists beyond a single chat session. Each subsequent code-generation prompt is then tied to a piece of that plan (“Implement module X as designed” or “Write unit tests for feature Y as specified”). The AI isn’t vibing in a vacuum; it’s following a breadcrumb trail that you (or previous AI steps) have laid out. This is orchestrated development, not stream-of-consciousness coding.
Notion-Driven Memory Architecture. Where do we store this trail of breadcrumbs? Ideally in a central, accessible knowledge hub that both humans and AIs can tap into. This is where a tool like Notion comes in. Notion – the popular all-in-one workspace for notes, docs, and project boards – can serve as the persistent memory for an AI-augmented project. It’s already used by many as a “second brain” to store and organize knowledge outside one’s head. In a dev context, Notion (or a similar wiki/issue system) becomes the place where requirements, design decisions, known bugs, and code snippets live in a structured way.
Why Notion? Notion’s flexibility lets you create pages for specs, tables for tracking tasks or prompts, and even embed code or diagrams – all updated in real-time as the project evolves. Crucially, new AI integrations mean LLMs can retrieve information from Notion or even operate within it. Unlike a standard code editor, Notion’s AI sees not just the last prompt, but potentially the entire project knowledge base. In effect, Notion provides long-term memory to the otherwise short-term memory of an LLM. One analyst observed that most AI coding tools have the “memory span of a goldfish,” forgetting context as soon as you switch tasks, whereas Notion’s AI features introduce a more sophisticated memory architecture that retains context across interactions. Similarly, AWS researchers note that memory-augmented agents (agents hooked up to external memory stores) can maintain context across multiple tasks and sessions, leading to far more coherent and strategic responses. It’s the difference between an AI that’s winging it in each prompt versus one that remembers the whole project history.
Issue Logs and Development History. A concrete practice here is to use an issue tracker or log of tasks that the AI consults and updates. Steve Yegge’s solution to vibe chaos, for example, was to create a lightweight issue tracker (which he codenamed “Beads”) for his AI coding agents. Instead of writing and forgetting TODO lists in markdown, the agent started logging every discovered bug or task as a structured issue (with unique IDs, statuses, and links) stored in a shared database. The effect was profound: no more “lost” work. “This behavior leads to problems in your code being perennially lost and rediscovered because they were never recorded… [but] with Beads, you’ll never lose track of work items again,” Yegge reports. The AI, upon noticing failing tests, would automatically file an issue like “Issue 397: Fix broken tests”, and then continue coding, ensuring the problem was noted for later. With a shared issue log, even multiple AI agents could coordinate without stepping on each other’s toes – they’d query the same list of open tasks, pick up the next item, and update statuses accordingly. In essence, the issue tracker became the single source of truth for work in progress, solving the orchestration problem.
Now imagine using Notion to host such an issue log or task board – one that the AI can read from and write to via an integration. Every time you prompt the AI, it’s aware of what’s done, what’s pending, and what’s blocked. Every time a new bug is found or a refactor is needed, it gets logged for triage instead of being forgotten. You’re no longer just vibe coding, you’re co-directing an AI-empowered development process.
Structured Prompt Libraries and Reusable Modules
Another pillar of sustainable AI-augmented development is reuse – of both code and prompts. In the frenzy of vibe coding, developers often treat AI prompts as disposable queries: “do this now, generate that snippet, OK thanks, bye.” This leads to repetitive work and inconsistency. A smarter approach is to build a library of proven prompts and code solutions that can be reused across projects and sessions, much like we build libraries of code.
Think of prompts as modular functions or API calls into the AI. For example, you might have a prompt template for “Generate a REST API endpoint given a data model and spec” or “Write unit tests for a function.” Instead of crafting that from scratch every time, you document it, refine it, and reuse it. Enterprises are already moving this direction. They treat prompts as assets – versioned, tagged, and tested like software artifacts. A recent report on prompt engineering best practices put it bluntly: *“The biggest shift in mindset is this: prompts are not temporary fixes or one-off tricks. They are long-lived, business-critical assets that need lifecycle management.”* In other words, don’t fire-and-forget your prompts; maintain them. Build a prompt library so that when your AI coding partner needs to do something (generate a migration script, create a UI component, etc.), you’re pulling from a known-good, organization-approved prompt rather than reinventing it on the fly.
This approach yields multiple benefits: consistency (everyone uses the prompt that follows company guidelines), efficiency (no duplicate prompt engineering for the same task), and trackability (you can improve a prompt over time and see that improvement propagate everywhere it’s used). Just as code libraries improve with each version, your prompt library gets better – and you avoid the AI equivalent of “copy-paste programming” in favor of systematic reuse.
On the code side, the principle is the same. AI can generate boilerplate rapidly, but if you let it regenerate similar code over and over, you’ll end up with a nightmare of slightly-different implementations. Instead, identify common modules and have the AI or human factor them out. For instance, after a few microservices built via AI, you might abstract a reusable authentication module or logging utility, and then prompt the AI to integrate that existing module rather than writing a new one. This reduces bugs (because that module is tested) and increases reliability (less new code = fewer new errors). Moreover, it teaches the AI to code with context – referencing existing code in your repository. Modern AI dev tools can be guided to use specific functions or follow repository patterns if you supply that context. A well-structured Notion page listing key internal libraries or showing code examples can serve as reference for the AI to mimic or call the right components.
Finally, maintaining a development history – decisions made, architectures tried, lessons learned – contributes to scalability. When a new developer or a new AI agent joins the project, they can onboard quickly by reading the history. It’s analogous to good documentation, except parts of it may be auto-generated or maintained with AI assistance. Memory architectures enable this; for example, an AI agent with access to version control or past conversation logs can answer “Why was library X chosen?” by pulling up the relevant discussion or commit message.
Unstructured vs. Orchestrated: A Side-by-Side Look
To crystalize the difference, let’s compare the typical vibe coding approach with the orchestrated AI-augmented engineering approach across a few dimensions:
Comparison of free-form “Unstructured Vibe Coding” vs. disciplined “Orchestrated AI-Augmented Engineering” along key dimensions.
On the left, Unstructured Vibe Coding often relies on the AI’s short-term memory only; context isn’t carried over well, leading to forgotten requirements or re-created bugs. Code and prompts are disposable – little gets reused, so similar problems get solved (and messed up) repeatedly. There’s poor traceability since plans and rationales are in the AI’s head (or buried in chat threads), not in a durable log. Bugs emerge and are fixed in a haphazard loop: code a feature, see it break, patch it, hope nothing else broke. This doesn’t scale – as the project grows, the lack of structure becomes a quagmire, with more time spent untangling issues or rewriting from scratch (the infamous “one prompt to build, one day to fix” scenario many have joked about).
On the right, Orchestrated AI-Augmented Engineering plugs those holes with memory, process, and reuse. The AI works with a persistent memory: requirements, design, and tasks stored in something like Notion or an issue tracker, ensuring it never forgets what the bigger picture is. Reusability is high – there are established prompt templates and code modules, so the AI isn’t reinventing the wheel each time. Traceability is built-in: every task or decision is logged (e.g., in an issue or commit), so you can always answer “why was this done?”. Feedback loops are proactive and continuous – you integrate testing into the AI’s workflow (yes, you can prompt AI to write tests and run them) and have the AI monitor for its own errors or improvements needed. And critically, this approach scales – as complexity grows, the AI has the tools to manage it (structured plans, shared memory, modular components), rather than collapsing under a spaghetti of ad-hoc prompts.
The result? You still get the magic of vibe coding – the rapid prototyping, the conversational development, the cross-functional collaboration – but now it’s grounded in a framework that catches errors, promotes quality, and accumulates knowledge.
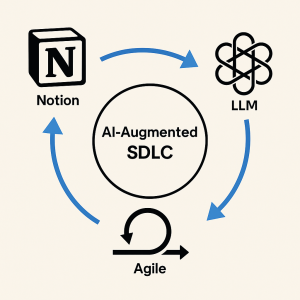
Notion + LLM + Agile = Your New Cognitive OS
Let’s paint the vision of how this all comes together in practice. Picture a development team co-piloted by AI, running on a cognitive operating system comprising Notion, an LLM, and Agile methods:
Notion as Memory & Coordination Hub: All project knowledge lives here – user stories, design diagrams, API specs, the prompt library, coding guidelines, and the live issue/task board. Notion’s pages and databases are the shared long-term memory. It’s searchable, versioned, and collaborative. Crucially, the AI has access to it. Instead of asking “What’s the spec again?”, the AI can fetch the spec from Notion. Instead of guessing previous decisions, it can look them up. Notion essentially externalizes the project’s brain so the AI (and any human) can tap into it anytime. It’s like having a senior engineer who never forgets anything and keeps the team organized – except it’s an app.
LLM as Reasoning Engine: The large language model (whether it’s GPT-4, Claude, or another) is the workhorse that generates code, plans, and analyses. It interfaces with Notion and other tools through prompts that are part of our structured library. We treat each prompt as an engineering intent – a high-level instruction that carries meaning in the project context. For example, a prompt might be “Generate data model classes for all entities defined in the spec on Notion page X” – a clear intent tied to a persistent artifact. The LLM reasons over these prompts, uses the provided context (from Notion, codebase, etc.), and produces output. Importantly, the LLM is also used for verification and QA: we routinely ask it to analyze its own output for errors, write tests, or cross-check against requirements. In effect, the LLM isn’t just coding blindly; it’s part of an iterative feedback loop ensuring quality.
Agile Workflow as Process Backbone: We still run sprints or Kanban-style continuous delivery, but many tasks are AI-augmented. In sprint planning, user stories from the Notion backlog might be broken into sub-tasks by the AI agent. Daily stand-ups might involve an AI-generated summary of progress or blockers (since all tasks are logged, the AI can summarize what got done yesterday and what’s next). When human developers pick up a task, they might use AI to generate the initial code, then refine it. When code is pushed, AI can automatically update the Notion docs or gene